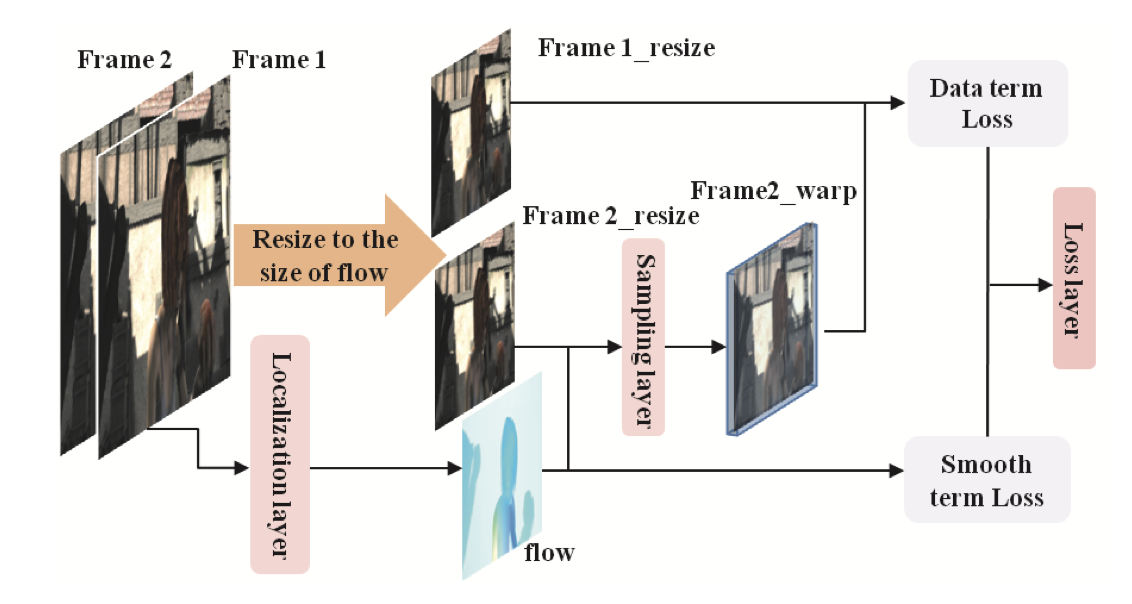
First paper to use unsupervised deep learning methods for optical flow, post FlowNet which proposed deep learning for supervised flow. They do this with coarse-to-fine generation via a CNN and imposing photometric pyramid losses on each generated flow. Performance is near but not the same as supervised SoTA of the time.
Apparently AAAI is not a good conference—I’m not going to take them on their word that there aren’t previous unsupervised DL approaches for OF.
Tags
Unsupervised Optical flow Deep learning Multi-scale pyramids, coarse-to-fine UNets Bilinear interpolation warping Upscaling flow Energy or loss minimization Gradient constancy
Architecture
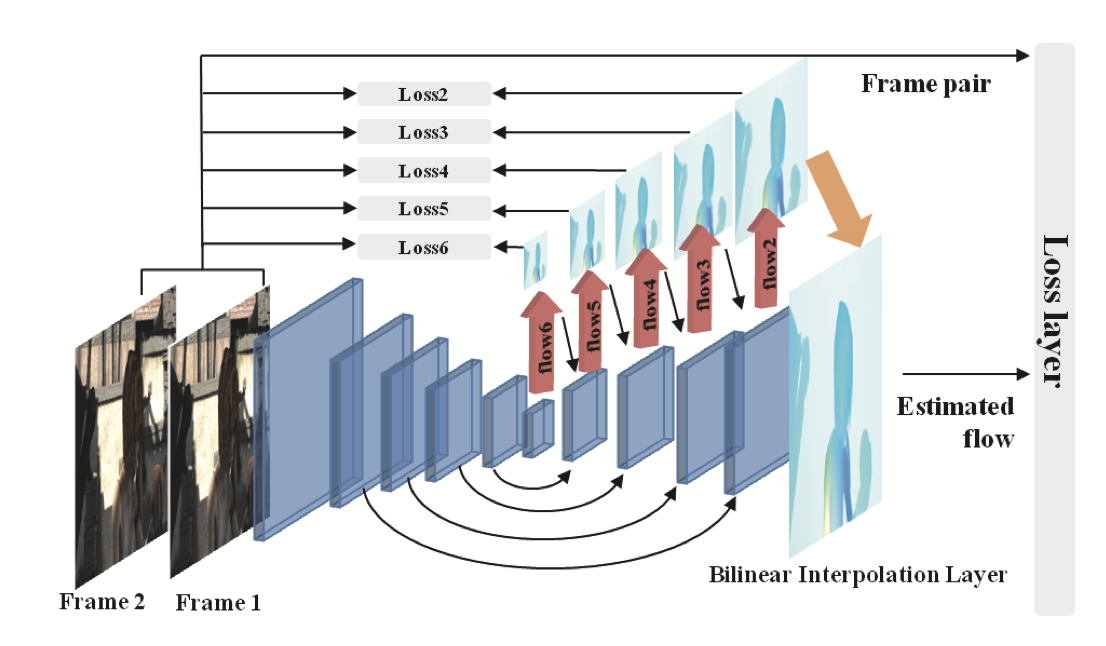
Apparently based off FlowNetSimple; very similar to UNet. The 6-channel (frame 1 & 2) input is fed into a convolutional network, which outputs the lowest level flow. Then up until 1/2 resolution, upconvolutional layers are used to generate subsequent level flows. Residual connections at each pair of equal resolutions, which is the hallmark of UNet. Backpropagation is done through the bilinear interpolation layer allowing end-to-end training.
Because the upconvolutional layer is probably more complex than a bilinear interpolation, the “averaging” effect of using low-level flows (as opposed to full-resolution flows) seems mostly mitigated.
Bilinear interpolation layer

Essentially the exact same as the current implementation I’m using, which allows gradients in pixels. Each flow pixel is distributed to the four integer-valued corners around it.
Loss
Notation is stolen from 2004.BBPW—High Accuracy Optical Flow Estimation Based on a Theory for Warping (Brox… 2004), and they don’t bother to specify it!
 There are two losses:
There are two losses:
- A photometric loss which penalizes:
- difference between two corresponding pixels;
- difference in gradient between two corresponding pixels (edge detection?)
- A smoothness loss which penalizes the gradient of flow Additionally, the Charbonnier penalty, which is a smoother version of absolute value, is used.
They use a loss schedule which weights lower level flows more strongly earlier on in training, then equalizes. Details are not given about the loss schedule, but cites Mayer 2016. This might be more necessary here because of how the higher-level flows are generated from the lower-level ones.
Training details
Augmentations:
- Mirror
- Translate
- Rotate
- Scaling
- Contrast
- Gamma
- Brightness
Other various training details:
- Adam optimizer, with learning rate 1e-4, decreasing 50% every 6000 iter. after 30000 iter.
- Finetune starts with learning rate 1e-5
- Batch size 64
Results
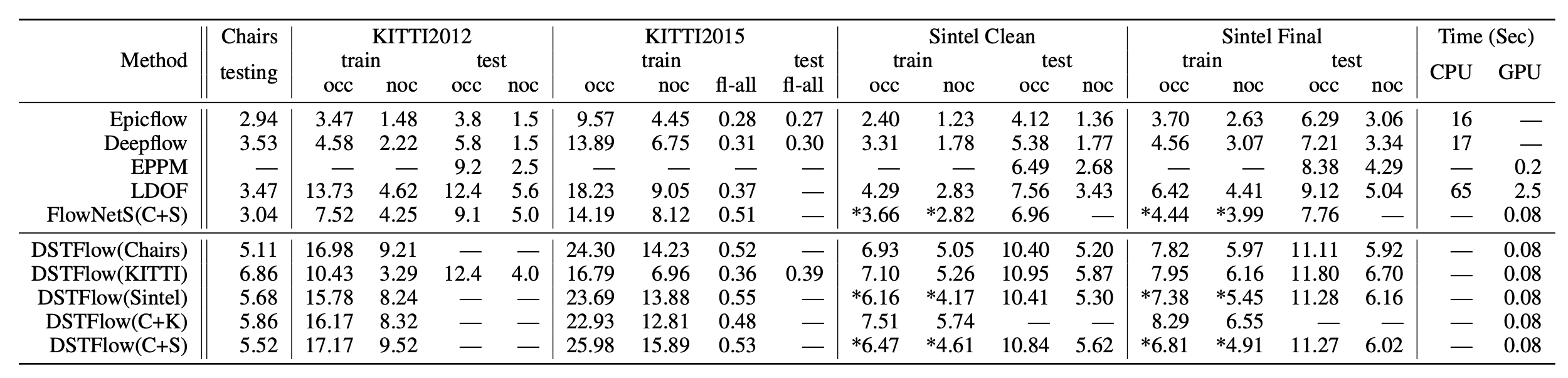
Cited
- 1981.H&S—Determining Optical Flow (Horn & Schunck, 1981)
- 1998—Independent component analysis of natural image sequences… (van Hateren and Ruderman 1998)
- 2004.BBPW—High Accuracy Optical Flow Estimation Based on a Theory for Warping (Brox… 2004)
- The generalized patchmatch correspondence algorithm (Barnes… 2010)
- Sift flow: Dense correspondence across scenes and its applications (Liu… 2011)
- A naturalistic open source movie for optical flow evaluation (Butler… 2012)
- Motion detail preserving optical flow estimation (Xu… 2012)
- Deepflow: Large displacement optical flow with deep matching (Weinzaepfel… 2013)
- Visualizing and understanding convolution networks (Zeilier and Fergus 2014)
- Unsupervised learning of visual representations using videos (Wang and Gupta 2015)
- Spatial transformer networks (Jaderberg… 2015)
- Epicflow: Edge-preserving interpolation of correspondences for optical flow (Revaud… 2015)
- Learning to compare image patches via convolution neural networks (Zagoruyko and Komodakis 2015)
- Full flow: optical flow estimation by global optimization over regular grids (Chen and Koltun 2016)
- A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation (Mayer… 2016)
- Learning dense correspondence via 3d-guided cycle consistency (Zhou… 2016)
Return: index