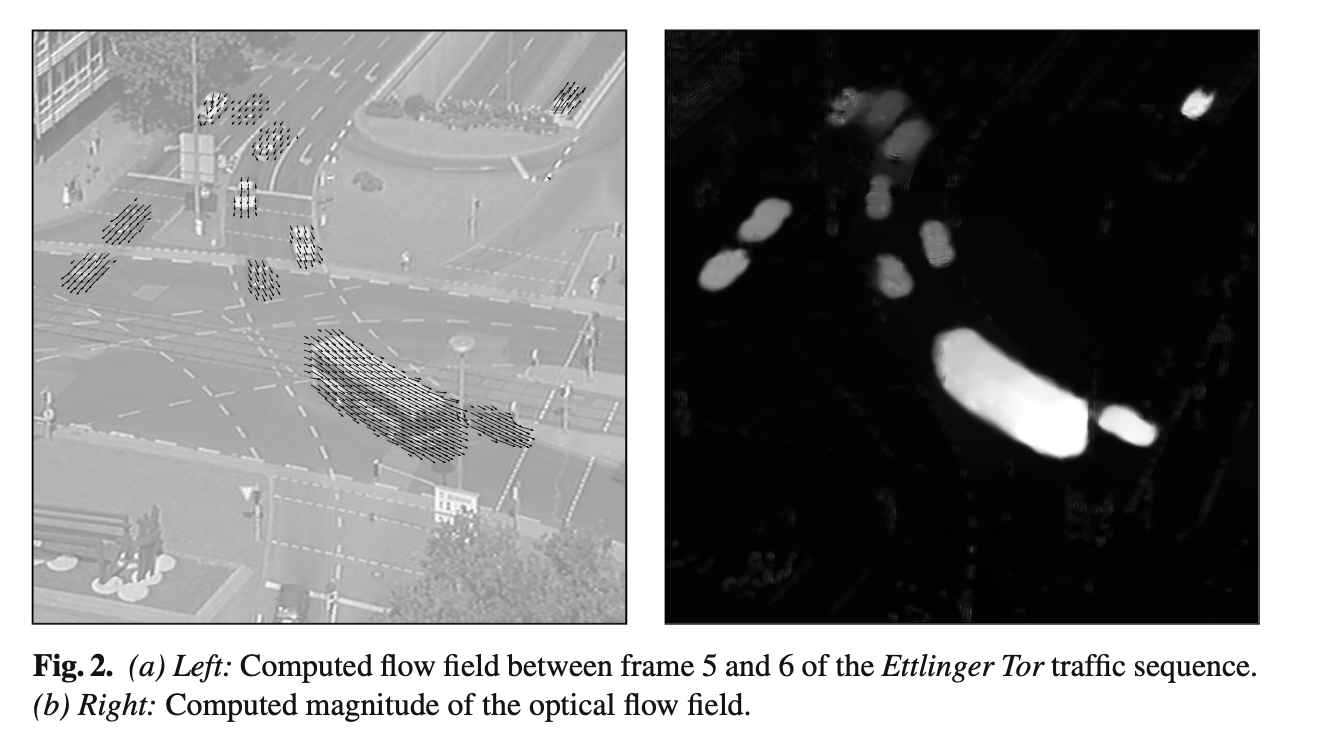
A classic old-school CV paper where optical flow is manually calculated & iterated upon for sequences of images (video). Like the classic approach, optical flow is formulated as satisfying constancy assumptions (color of a pixel does not change) and smoothness constraints (flow should be piecewise smooth). They use the variational method, i.e. modeling optical flow as a function.
Tags
NOT deep learning Calculus of variations Unsupervised Optical flow Multi-scale pyramids, coarse-to-fine Energy or loss minimization Gradient constancy Smoothness constraints
Advancements in the energy function
These all seem cool, but unfortunately ablation studies weren’t a thing in 2004, so I have no idea how each of them actually contributes to better performance.
De-linearization
Let be the pixel values of the image. The first improvement they do compared to H&S is to remove the implicit linearization in the brightness constancy (which they call grey-value constancy) equation:
While the first constraint involves partial derivatives and thus assumes the image changes linearly, flow displacements may be sufficiently large (and the images sufficiently quantized) that this is not the case. The latter constraint is now nonlinear due to the application of , but more suitable for large displacements. However, it admits the existence of many local minima (which is why optical flow is hard).
Gradient constancy
It was impossible for methods like H&S to deal with changes in shading. In order to be able to handle shading, we can also formulate the gradient constancy constraint, which is similar to the grey-value constancy constraint but only applies to the gradient of the image. Let ; then this constraint can be formulated as
and later on they set for easier notation. Since the gradient is not modified by global brightness changes, this assumption is a bit more adaptable.
On the benefits of this assumption in particular, they write
The [gradient constancy] constraint is particularly helpful for translatory motion, while [the linear grey-value constancy] constraint can be better suited for more complicated motion patterns.
Note that F&W Optical Flow Overview discusses similar gradient constancy assumptions, so it seems like that this assumption is not really new to this paper. Additionally, there are downsides; patterns that are rotating or sheared will be penalized under the gradient constancy assumption.
The approach
Energy formulation
The photometric loss is
and the smoothness loss is
where is the Charbonnier penalty and the second gradients are respect to respectively. As usual, the whole energy functional is equal to a weighted sum of these two terms:
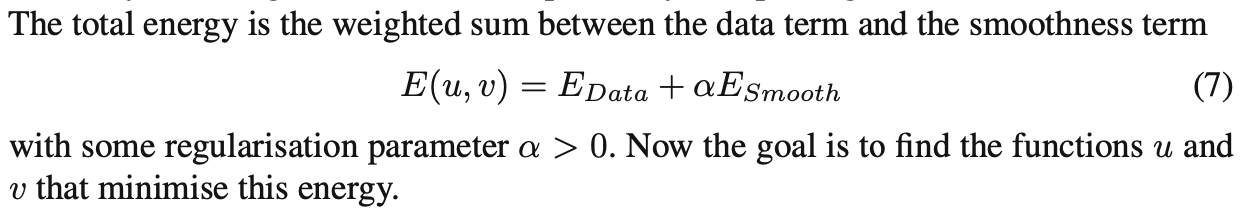 Apparently the smoothness loss allows piecewise smoothness, and is also a “total variation” loss, but I don’t understand why it incentivizes piecewise smoothness (as opposed to general smoothness).
Apparently the smoothness loss allows piecewise smoothness, and is also a “total variation” loss, but I don’t understand why it incentivizes piecewise smoothness (as opposed to general smoothness).
Minimizing the energy
This step involves a lot of math. Essentially, the Euler-Lagrange equation from the calculus of variations states that a minimizer of the energy functional satisfies
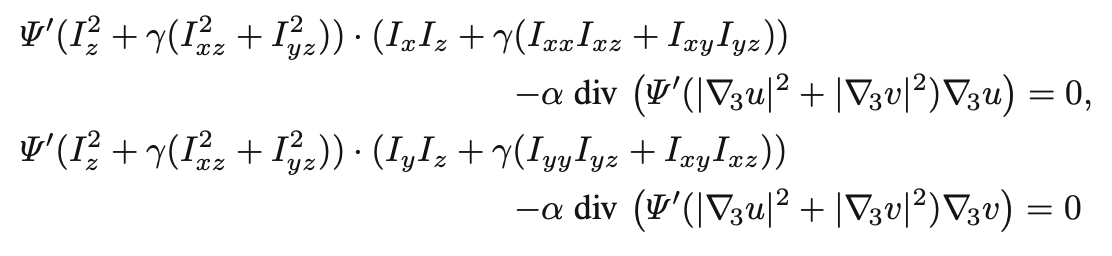 The first equation corresponds to and the second to ; the first half of each equation corresponds to the term and the second to the term. The minimization process is iterative; I’ll describe it later. The terms denote different approximations of partial derivatives (i.e. .)
The first equation corresponds to and the second to ; the first half of each equation corresponds to the term and the second to the term. The minimization process is iterative; I’ll describe it later. The terms denote different approximations of partial derivatives (i.e. .)
Coarse-to-fine process Minimization is done in a multi-scale way. Scaling involves scaling down by a factor among the and dimensions. First, minimization is done over the lowest scale. Once it’s converged, the flow is upscaled(? actually it’s not super clear) to use as initialization for the next scale.
Big picture The equations need to be linearized in order to be solved with normal numerical methods. Thus we do something similar to EM:
- Set .
- Replace most (but not all) of the s with s, then the rest with such that it’s linear in (or in this case ).
- Solve for (with an inner iteration), and add them back to to get .
- Rinse and repeat with . The idea is that will converge to a fixed point . This is called “fixed point iteration”; when a fixed point is reached, it solves the original equation. When we get something that solves the original equation, it is (probably) a minimizer of .
Nowadays, I think we’d just use a neural network to minimize that objective. Would it be better at it? Probably? It’s kind of shocking to me how this is basically the modern method for unsupervised optical flow, except we have neural nets instead of shitty equation solvers.
Theory of warping
The authors promise a theory of warping, i.e. that warping is theoretically optimal. One of their comments is exactly what I’ve been thinking about for a while:
Thus, the estimated used to have a magnitude of less than one pixel per frame, independent of the magnitude of the total displacement.
I don’t really get the theory; I’m going to read the reference [17] and maybe come back to it?
Cited
- 1981.L&K—An Iterative Image Registration Technique with an Application to Stereo Vision (Lucas & Kanade, 1981)
- 1986.N&E—An Investigation of Smoothness Constraints for the Estimation of Displacement Vector Fields from Image Sequences (Nagel & Enkelmann, 1986)
- 1989.Fwork—A Computational Framework and an Algorithm for the Measurement of Visual Motion
- 1992.ROF—Nonlinear total variation based noise-removal algorithms
- 1996.B&A—The Robust Estimation of Multiple Motions. Parametric and Piecewise-Smooth Flow Fields (Black & Anandan, 1996)
Cited By
Return: index