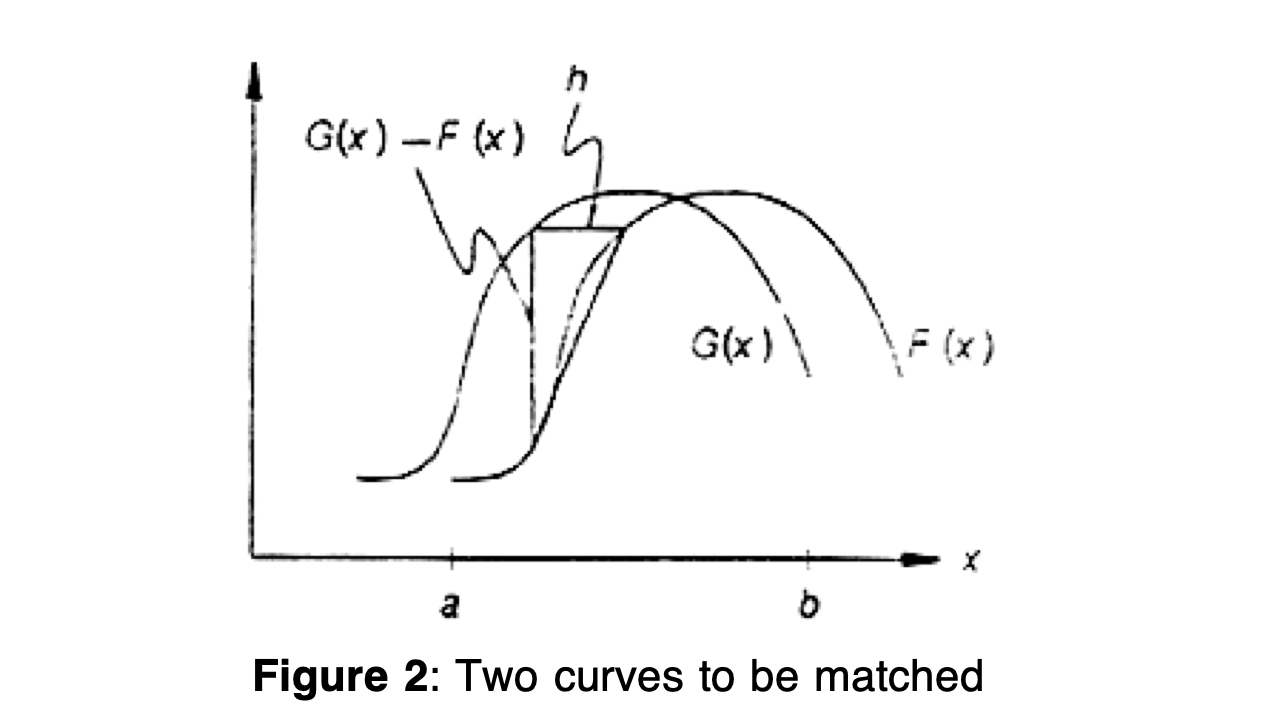
The classic local method for computing optical flow. It’s actually not an optical flow paper; they tackle what is called the image registration problem. For example, if you have many exposures of the same image (e.g. in astrophotography), but each image is slightly offset due to noise, the different exposures need to be aligned before combining in order to create a sharp image.

In contrast to optical flow, one global distortion is expected as opposed for the entire image or region. This does make it suitable for optical flow problems where the flow is expected to be relatively constant in an area; applying L&K locally gets you an estimate of the optical flow at that point.
Key assumptions. Local methods like L&K work only in a narrow range of cases.
- Optical flow is relatively constant in the given region of the image. (This is roughly equivalent to the smoothness assumption from H&S.)
- Optical flow is relatively small (around less than pixel).
- We have no textureless interiors we care about, which would erroneously have optical flow. Unlike H&S, edge optical flows cannot be propagated inwards to the interior of an object. Additionally, L&K is typically used to get sparse flows. There is, to my knowledge, no guarantee of smoothness.[^1: There may be, but it’s not mentioned in the paper.]
By incorporating the visual content of many pixels into the estimate of a single optical flow vector, L&K can get more accurate & robust (to noise) estimations of individual flows. However, it is difficult to get dense estimations.
Tags
Multi-scale pyramids, coarse-to-fine NOT deep learning Old school Optical flow Stereo vision Unsupervised Local methods Unsupervised Affine, parameterized optical flow
The approach
We are given a picture of size , i.e. with pixels. Naively, if the flow is restricted to in each direction, we can attempt to iterate over all possibilities, yielding a search time of . L&K propose a hill-climbing method (i.e. gradient-descent type method) which uses gradients of the image (or approximations, i.e. ) in order to estimate which step to take next. Thus, unless a coarse-to-fine approach is used, optical flows should be pixel.
Given an image and a second image , we wish to find a single vector which minimizes (primarily) the norm:
We use an iterative method. In particular, let and , then
or (second variant)
The rough/intuitive derivation of these is as follows. Suppose we have the correct . Then
which implies after rearranging. So then given an estimate , we can estimate the error as such.
These two variations are just different weighting methods for different terms of that form. Note that a lot of linearizations are used in the derivation of these formulas.
Low frequency signals
Here’s a really interesting passage from the paper:
 Smoothing via blurring kind of implicitly enables a coarse-to-fine approach. Thus I’m wondering if instead of using a pure pyramid loss, we could blur the image significantly instead to induce the same low-frequency gradients. Right after this, they propose using a coarse-to-fine strategy in order to speed up calculations.
Smoothing via blurring kind of implicitly enables a coarse-to-fine approach. Thus I’m wondering if instead of using a pure pyramid loss, we could blur the image significantly instead to induce the same low-frequency gradients. Right after this, they propose using a coarse-to-fine strategy in order to speed up calculations.
Generalizations and applications
First, they extend to multiple dimensions. The vectorized form of the second equation is:
Then, they discuss a generalization of the above approach to a general affine transform , where both and are optimized for. Interestingly, I think this would be super flexible with scaling of image objects, whereas most optical flow methods would struggle with this.
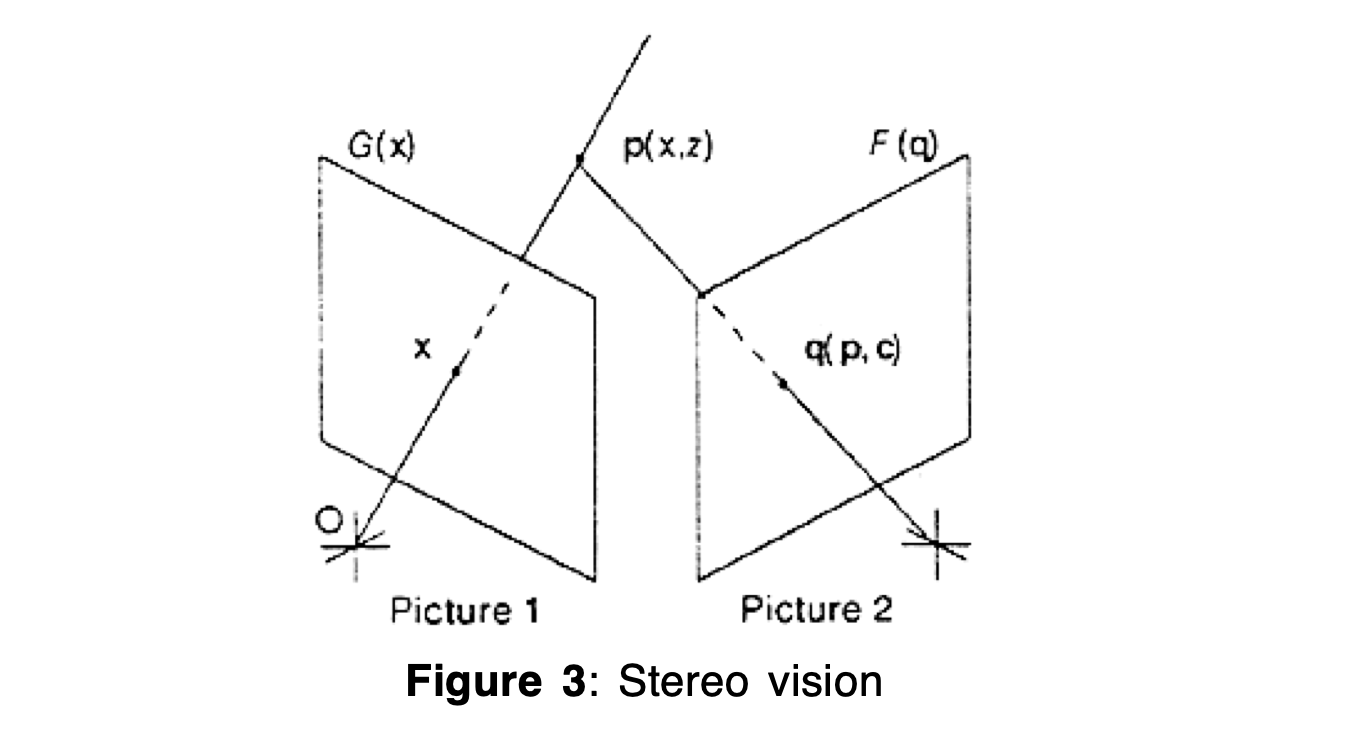 Finally, they describe an application of this approach to stereo vision, where we want to estimate the relative poses of the two cameras as well as the depth of the image. The affine transform mentioned in the previous part is useful here; I didn’t read it very carefully.
Finally, they describe an application of this approach to stereo vision, where we want to estimate the relative poses of the two cameras as well as the depth of the image. The affine transform mentioned in the previous part is useful here; I didn’t read it very carefully.
Cited
None
Cited By
- 2004.BBPW—High Accuracy Optical Flow Estimation Based on a Theory for Warping (Brox… 2004)
- ! 2005.F&W—Optical Flow Estimation (Fleet & Weiss, 2005)
Return: index